單相穩壓器故障分析 小白也能看懂的實用指南,值得收藏!

在現代電器和工業應用中,單相穩壓器是保障電壓穩定、保護設備安全的關鍵裝置。一旦出現故障,很多人,尤其是新手或電子愛好者,可能會感到無從下手。本文旨在為您提供一份清晰、易懂的單相穩壓器故障分析指南,即使是小白也能快速掌握核心要點。為了便于理解,我們將以上海民熔這類常見品牌中典型的PCB(印刷電路板)電路板結構為例進行說明。
一、單相穩壓器基礎與PCB結構
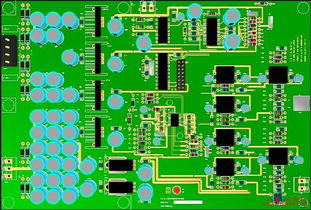
在深入故障分析前,我們先簡單了解單相穩壓器的工作原理和PCB電路板的角色。單相穩壓器通過自動調節輸入電壓,輸出一個穩定的電壓(如220V),以保護連接的設備免受電壓波動的影響。其核心控制部分通常集成在一塊PCB電路板上,上面布滿了電阻、電容、變壓器、繼電器、控制芯片(如比較器或微處理器)等電子元件。上海民熔等品牌的穩壓器,其PCB設計通常注重可靠性和易維護性。
二、常見故障現象與快速診斷
當穩壓器出現問題時,通常會表現出以下癥狀。您可以對照檢查:
- 無輸出或輸出不穩定:設備無法啟動或頻繁重啟。
- 可能原因:輸入電源線松動、保險絲熔斷、PCB上的主繼電器損壞或控制電路故障。
- 輸出電壓過高或過低:用萬用表測量輸出端電壓異常。
- 可能原因:PCB上的電壓采樣電路(涉及電阻、電位器)失調,或控制芯片失效。
- 異常噪音或發熱:穩壓器工作時發出嗡嗡聲或燙手。
- 可能原因:內部變壓器或電感松動,PCB上的散熱不良,或功率元件(如MOS管)過載損壞。
- 顯示面板異常:如果穩壓器帶顯示屏,出現亂碼或不亮。
- 可能原因:PCB上的顯示驅動電路故障,或供電部分有問題。
三、PCB電路板關鍵點檢測(小白安全操作指南)
重要提示:在進行任何檢測前,務必斷開電源,并確保電容器放電,以防觸電!如果您是新手,建議在專業人士指導下操作。
針對上海民熔等品牌的PCB,您可以重點關注以下幾個易出問題的區域:
- 電源輸入部分:檢查PCB上的保險絲是否熔斷(可用萬用表通斷檔測試)。
- 控制芯片周邊:觀察芯片引腳有無虛焊、燒焦痕跡。芯片是PCB的“大腦”,其故障常導致整體失靈。
- 繼電器和功率元件:這些是PCB上較大的元件。繼電器觸點燒蝕會導致輸出不穩定;功率元件損壞可能引起無輸出或過熱。
- 電位器和電阻:用于電壓調節的電位器(一個可旋轉的小元件)容易因灰塵或老化導致接觸不良,從而影響輸出電壓精度。
四、簡易維修與預防措施
對于小白來說,復雜的焊接更換可能較難,但可以嘗試:
- 清潔PCB:用軟刷和酒精輕輕清潔電路板,去除灰塵,有時可解決接觸不良問題。
- 緊固連接:檢查所有接線端子是否擰緊,包括PCB上的插接件。
- 更換保險絲:如果只是保險絲壞了,更換同規格的新保險絲可能就能修復。
為了減少故障,日常應保持穩壓器通風良好,避免過載使用,并定期檢查。
五、何時尋求專業幫助
如果您檢測后問題依然存在,或者對PCB操作沒有把握,切勿強行維修。此時應聯系廠家(如上海民熔的售后服務)或專業電工。穩壓器涉及高壓電,安全第一!
###
單相穩壓器故障雖然看似復雜,但通過系統分析PCB電路板上的關鍵點,小白也能快速定位常見問題。收藏這份指南,當您的穩壓器“罷工”時,不妨按步驟排查,或許能省下不少維修費!記住,實踐出真知,但安全永遠是前提。